Частота
Вычисляет характерную частоту действий объекта (повторение действий за промежуток времени). Используется для обнаружения аномалий, таких как:
- пользователь запустил редко используемый процесс
- использовался файл с редким расширение файла для пользователя
Описание алгоритма
- К данным индексов источников применяется общий и временной фильтры
- Каждая запись данных приводится к общему виду согласно настройкам обрабатываемых полей
- Данные разбиваются по уникальным сочетаниям значений обрабатываемых полей
- Каждая часть данных полученная на шаге 3 разбивается на интервалы, в каждом интервале подсчитывается количество документов
- По количеству документов вычисляется статистика для каждой разбивки по полям
Входные параметры
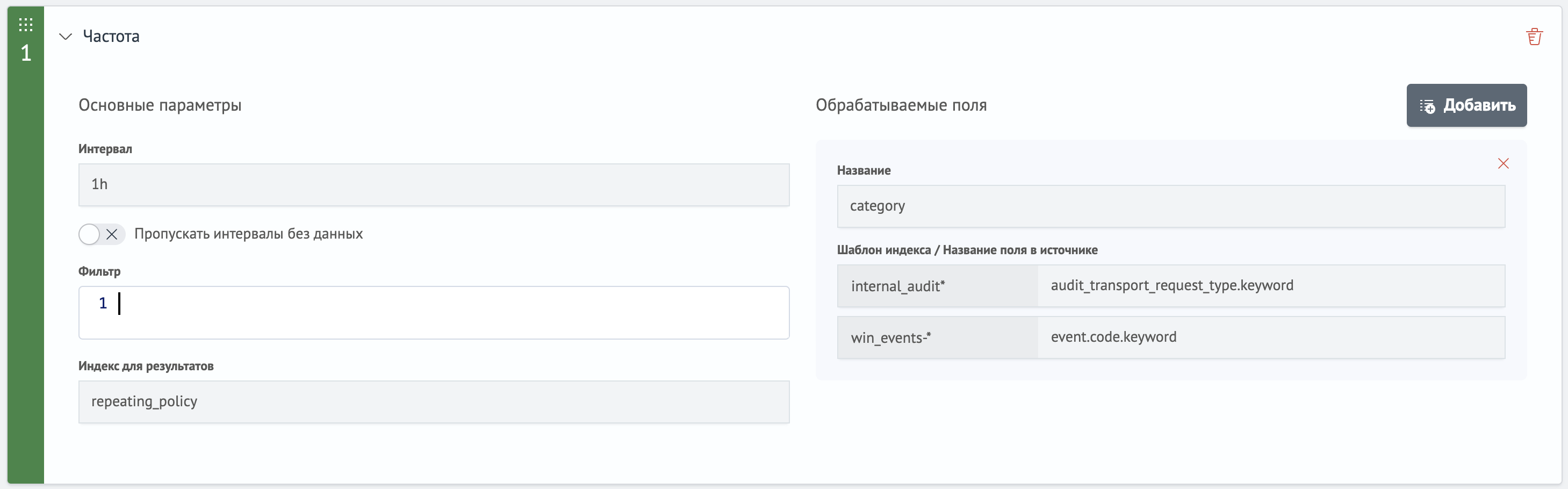
- Фильтр - общий фильтр источников (используются выражения из команды search)
- Индекс для результатов - индекс в который записываются результаты выполнения
- Обрабатываемые поля - маппинг полей источников на поля результата
- Название - название поля в индексе с результатами
- Шаблон индекса / Название поля в источнике - список шаблонов индексов и соответствующих полей в них, которые будут извлекаться в результат
- Интервал - величина промежутков времени на которые разделяются данные источников.
Примеры заполнения:1yгод,1Mмесяц,1dдень,1Hчас,1mминута,1sсекунда - Пропускать интервалы без данных - пустые интервалы не учитываются в расчете статистики
Входные данные
Входные данные определяются индексами и временным интервалом в общих настройках.
Выходные данные
В результате выполнения алгоритма в индексе результатов появляется несколько записей. Каждая запись содержит статистику по всем интервалам времени для обрабатываемых полей.
_meta.calculation.id- идентификатор нас�тройки алгоритма в политике профилирования_meta.calculation.type- тип алгоритма_meta.execution.start_time- время запуска политики профилирования_meta.execution.id- идентификатор запуска политики профилирования_meta.object.identity- массив идентификаторов UBA объекта_meta.object.id- технический идентификатор UBA объекта_calculation- результат выполнения алгоритма_calculation.extended_stats- расширенная статистика по всем интервалам_calculation.percentiles- процентиль по всем интервалам_calculation.span- величина интервала_calculation.by_fields- сочетание значений обрабатываемых полей для которых рассчитана статистика
Пример json-объекта результата
{
"_index": "repeating_policy",
"_id": "HP9MmY4BcdU8iNUUlvMz",
"_score": 8.92765,
"_source": {
"_meta": {
"calculation": {
"id": "oTHfW44BwooGBkrZbNg_",
"type": "repeating"
},
"execution": {
"start_time": "2024-04-01T10:55:16.761Z",
"id": "DP9MmY4BcdU8iNUUlfMZ"
},
"object": {
"identity": [
"romanov.a@volgablob.ru",
"89166788776",
"romanov.a"
],
"id": "9186db972bafeafed6411ab644d0313bb1def204"
}
},
"_calculation": {
"extended_stats": {
"count": 25,
"min": 4,
"max": 62,
"avg": 47.24,
"sum": 1181,
"sum_of_squares": 58917,
"variance": 125.06239999999991,
"variance_population": 125.06239999999991,
"variance_sampling": 130.27333333333323,
"std_deviation": 11.183130152153282,
"std_deviation_population": 11.183130152153282,
"std_deviation_sampling": 11.413734416628644,
"std_deviation_bounds": {
"upper": 69.60626030430657,
"lower": 24.873739695693438,
"upper_population": 69.60626030430657,
"lower_population": 24.873739695693438,
"upper_sampling": 70.0674688332573,
"lower_sampling": 24.412531166742713
}
},
"percentiles": {
"values": {
"1.0": 4,
"5.0": 32,
"25.0": 44,
"50.0": 49,
"75.0": 53,
"95.0": 61,
"99.0": 62
}
},
"span": "1h",
"by_fields": {
"category": "4720"
}
}
}
}