Общая информация
Раз�граничивайте поток индексируемых данных
Не стоит записывать данные по разным информационным системам в один индекс.
Например, если у вас есть данные по событиям в Linux и событиям с Windows, стоит разделить их на соответствующие индексы. Индексирование с разных источников в один индекс может привести к потенциальных проблемам в части хранения структуры данных.
Ограничивайте временной фильтр при поиске
Используйте для поиска диапазон времени, соответствующий целям выполнения поискового запроса. Например, при поиске конкретного события за последний час сократите временной диапазон, изменив значение по умолчанию Последние 24 часа.
Настройки маппинга
Настройки маппинга позволяют выставить тип данных полей для индексируемых событий. Помимо стандартных типов данных (integer, long, date и т.д.) стоит обратить внимание на типы text и keyword.
Тип поля text анализируется во время индексации, а поле keyword - нет. Это означает, что text при индексировании разбивается на отдельные слова, что обеспечивает частичное совпадение. За счет этого text используется для полнотекстового поиска, который задействует больше ресурсов кластера. Поля типа keyword индексируются как есть и обеспечивают полное совпадение.
На примере по данным win_events выполним поиск по событиям added-user-account для различного маппинга поля event.action. Для этого необходимо выполнить следующие шаги:
-
Выполнить переход к поиску
Навигационное меню - Основное - Поиск -
В строке поиска выполнить следующий запрос:
source win_events
| search event.action="added"
| stats count by event.action
При выполнении данного запроса для поля event.action применяется маппинг типа text, поэтому поиск будет выполняться по всем событиям, содержащим значение added.
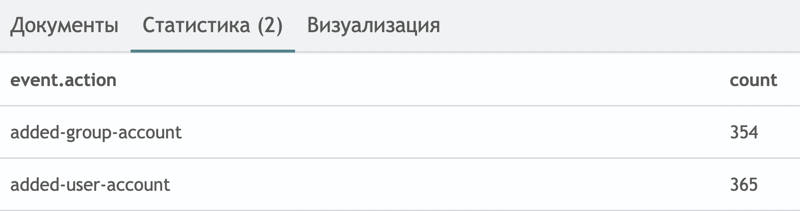
- Попробовать выполнить такой же запрос с маппингом типа
keyword:
source win_events
| search event.action.keyword="added"
| stats count by event.action
В результате выполнения такого запроса поиск ничего не вернет. Это связано с тем, что для маппинга keyword поисковый движок будет искать точное совпадение по поиску. Для обнаружения событий необходимо точно указать значение для поиска. В данном случае нужно выполнить следующий запрос:
source win_events
| search event.action.keyword="added-user-account"
| stats count by event.action
При таком запросе поисковый движок вернет все события по точному совпадению поля event.action.

Настройки индексов
Правильный выбор числа shards поможет равномерно распределить индекс по всем узлам данных в кластере. Их количество должно определяться потоком индексируемых данных. Рекомендуется использовать настройку 30-50 Гб на одну единицу данных. Например, если планируется накапливать около 300 Гб данных в день, то для такого индекса оптимально иметь около 10 shards.
В общем виде запрос на настройку индекса с параметрами shards и replicas выглядит следующим образом:
PUT <index-name>
{
"settings": {
"number_of_shards": <number_of_shards>,
"number_of_replicas": <number_of_replicas>
}
}
После применения настроек для индекса изменить их будет невозможно. Для примен�ения новых настроек над теми же данными нужно создать новый индекс с нужными настройками и выполнить индексацию ещё раз.